We are looking to recruit a talented bioinformatician to work within the MetaboLights team at the European Bioinformatics Institute (EMBL-EBI) located on the Wellcome Trust Genome Campus near Cambridge in the UK. You will work closely with a consortium of 8 European partners on the METASPACE project.
METASPACE will enable untargeted spatial metabolomics for translational research and clinical applications by providing novel bioinformatics tools, and to demonstrate their potential using several case studies relating to personalised health, precision medicine and quality of life in chronic afflictions.
You will work with other bioinformaticians, domain experts and software engineers on the development of novel database-driven spectral and spatial algorithms, machine learning approach for multiple-mass fingerprinting, development of web services and more. You will also help coordinating outreach and training, both in terms of online and face-to-face training, in collaboration wit EMBL-EBI’s professional outreach and training team.
The EBI is part of the European Molecular Biology Laboratory (EMBL) and it is a world-leading bioinformatics centre providing biological data to the scientific community with expertise in data storage PuTTY SSH SOCKS proxy , analysis and representation. EMBL-EBI provides freely available data from life science experiments, performs basic research in computational biology and offers an extensive user training programme, supporting researchers in academic and industry. We are part of EMBL, Europe’s flagship laboratory for the life sciences.
Metabolomics is a growing field and the number of organisms being studied is constantly increasing as is the number of metabolites being discovered. With this growth comes a steady increase in the amount of metabolomics data and the need to ensure that we capture this information in persistent open formats and databases.
The COSMOS project (COordination Of Standards In MetabOlomicS, http://www.cosmos-fp7.eu/) has been created to improve the adoption of open standards for metabolomics data, annotation with agreed metadata, and support by open source data management and capturing tools. COSMOS delivers an ecosystem of formats, tools, and resources such as MetaboLights (http://www.ebi.ac.uk/metabolights/), a database for capturing information obtained in metabolomics experiments.
There has always been a bit of confusion in the terminology around the subject of computer-assisted structure elucidation (CASE), so let’s define some terms:
Structure Elucidation – Determining the structure of truly unknown compounds de-novo from spectroscopic (or earlier by hard core chemistry :)) experiments
Structure Identification – Recovering the structure of already known compounds from databases or printed reference material (including experimental sections of the primary literature)
Dereplication: Same as 2.
The more we discover, the more likely it will be that we are able to de-replicate by database lookup. This of course requires well curated and developed open access databases that cover many chemical compounds/metabolites.
In organic chemistry, spectroscopic databases for structure identification where published quite early puttygen download , albeit as closed-access, commercial systems. The most widely used examples is probably the SpecInfo database which now seems to be marketed by Wiley and the more recently (considering the 40-year horizon of the topic :)) published ACD/Labs spectral libaries and management system. Wolfgang Robien in Vienna has been developing NMR spectral databases and prediction tools for a long time.
The general way of searching in such databases would be to measure an NMR spectrum of your isolated unknown compound, perform a peak picking and search the database using this peak picking (a feature vector, if you wish).
In the early 2000’s my Stephan Kuhn in my group developed the NMRShiftDB database which was the first open access, open source, open submission, web-based NMR database where you can now test how this all works without running into pay walls. Stephan has left the lab and now runs version 2 of this database in collaboration with the NMR lab at the department of chemistry at the University of Cologne.
One caveat: It is much easier to search for carbon-13 NMR spectra or mass spectra than for proton NMR spectra. The latter has rarely been addressed, not the least because of the lack of full spectrum proton data to which you could match a real-life proton spectrum. Peak-picking proton NMR spectra is problematic often due to overlap and complex coupling patterns.
Take for example the carbon-13 spectrum of pinocarveol, both from the metabolomics section of BioMagResBank (BMRB). Using your NMR software’s peak picking method, you would end up with this list of NMR signals. If you have a decent browser, such as FireFox, you can use the CMD (on mac) or CTRL key and select the chemical shifts in the table linked above. If not, here they are:
In preparation for a talk about structure elucidation of unknown chemical compounds at AISBM in Paris in October, I laying out a bit of the work that others as well as my group have done over the past 40 years in this area. The topic of this AISBM meeting is “Challenges and advances in the annotation and de novo identification of small molecules of biological origin”. I am going to address the problem of computer-assisted structure elucidation (CASE) of unknown compounds in organic chemistry in general and refer to the sub-problem of natural products and metabolites when needed.
Generally speaking, we are talking about the problem where you have an evidence that there is a compound in a biological system or your flask but you don’t know the structure of it. By structure, I mean ideally the fully defined stereo isomer but at least the fully defined constitutional isomer.
I have reviewed the problem of computer-assisted structure elucidation (CASE) a few times in the context of Natural Products Structure Elucidation (Steinbeck 2001, Steinbeck 2004).
Assume, for example, that you are working on a newly discovered medicinal plant and want to discover the compound or set of compounds responsible for the activity.
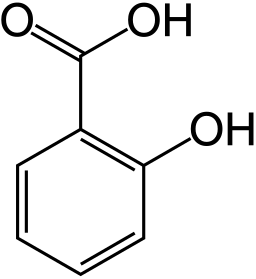
Willow Tree (Courtesy of Wikipedia). The bark contains Salicylic Acid and was used for a long time as a pain reliever and fever reliever.
How could one find out that the structure of the active ingredient is as follows?
Constitutional formula of salicylic acid (Courtesy of Wikipedia)
The evidence you’ve got could come from a chromatographic experiment where you have become interested in a particular peak that shows a biological activity.
HPLC chromatogram of a perfume mixture (courtesy of Wikipedia). Each of those peaks is at least one compound. What is the structure of the compound under the leftmost signal?
In our context, the information for determining this information comes from spectroscopic information – NMR and/or Mass Spectrometry (MS). In order to retrieve this information, we need to isolate the compound using separation techniques such as HPLC or use hyphenation techniques.
In the next post, I will elaborate on some of case scenarios that we might be facing in structure elucidation.
References:
Steinbeck, C. “The Automation of Natural Product Structure Elucidation..” Current Opinion in Drug Discovery and Development 4.3 (2001): 338–342. Print.
Steinbeck, C. “Recent Developments in Automated Structure Elucidation of Natural Products.” Natural Product Reports 21.4 (2004): 512–518. Print.
I am delighted to report that the latest Impact Factor for the Journal of Cheminformatics is 4.54 which is a huge improvement over the 3.59 from 2013. Congratulations and thanks to out authors PuTTY , the editorial and production team, our editorial board and my co-editor-in-chief David Wild for making this possible.
Here I document the assembly, which was really easy due to the excellent videos by Daniel Reetz on YouTube. I recommend watching them all before even starting to do anything with the kit. Regarding tools needed for the assembly: An electric drill and an electric screw driver are really handy. You’ll need a Philips and a hex tip screwdriver. A rubber hammer is useful but a normal hammer and a piece of scrap wood will do. I am not going to repeat what Daniel has documented so perfectly but just show a series of pictures that document the assembly. This is essentially done in an afternoon.
The Scanner Base
The Cradle Base
Lever Arms with Skateboard Bearings
Base with Cradle Base and Lever Mechanism assembled
I love books. Real books, made of paper, ideally hard cover and properly bound with needle and thread. And I have assembled a nice library over time.
On the other hand, due to peculiar choices of where to live and where to work, and due to the nature of my job, I essentially live on the road and in the air. That is incompatible with carrying around heavy, beautiful and sensitive books.
Over the years I have more and more reduced the weight of my backpack and recent improvements in offline reading apps for the magazines I read (C’t, Make Magazine, Nature) make it possible that I can now read all of them in the air and offline on my iPad without carrying around the paper and its weight. At any given time, however, I am also reading a book from my tall FIFO stack of books. Buying them as ebooks is not an option for me, due to my love for physical books and other concerns about DRM and loss of access.
Due to another passion, Makeing, Open Source Software and Open Hardware, I came across the fantastic DIYBookScanner project. After Daniel Reetz, a key figure of this movement, released the plans for an open hardware standard bookscanner kit, I knew it was time. Because of time constraints, I decided to buy pre-cut parts from http://diybookscanner.eu/. I hope to build one from scratch soon at MakeSpace Cambridge.
But for now I would like to report on my progress with the book scanner kit from http://diybookscanner.eu. I decided to buy the base kit and get the cameras, foot pedal and USB hub from Amazon.
The kit arrived in a nice, light and compact package. The purchase includes video chat support for the assembly, which I didn’t need due to the extensive online documentation.
Parts where each wrapped in shrink wrap.
I will report on putting this together in a following post. For now I would like to congratulate the folks at http://diybookscanner.eu/ for their excellent product.
Towards a better understanding of lipid metabolism through studies of Drosophila Lipidomics
Christoph Steinbeck, Julian Griffin, Steve Russell
Fruit fly (Drosophila melanogaster, male), Courtesy of Max Westby
This project will bring together Drosophila experts at the University of Cambridge (Prof. Steve Russell, Dept of Genetics and Cambridge Systems Biology Centre), the Lipidomics lab led by Julian Griffin at the MRC Unit for Human Nutrition Research/Biochemistry, University of Cambridge and the Computational Metabolomics Group led by Christoph Steinbeck at the European Bioinformatics Institute in Hinxton to extensively study the lipidomics of Drosophila. The student will grow up a number of Drosophila mutant models related to lipid metabolism, isolate fat pads and perform analysis using high resolution mass spectrometry. The data will be modelled within the Computational Metabolomics Group to identify differences between the mutants, and explore how the Drosophila lipidome is regulated.
For this BBSRC-funded project, only candidates with a UK passport are eligible. Please email steinbeck@ebi.ac.uk if you are interested.
Jean-Claude Bradley receiving the Blue Obelisk award presented by Egon Willighagen in an improvised ceremony during the ACS meeting in Chicago 2007 (Chris Steinbeck behind the camera). Picture licensed CC-BY.
As announced today by Drexel University, Open Science Pioneer and recipient of the Blue Obelisk award Jean-Claude Bradley died yesterday. He was a member of the editorial board of the Journal of Cheminformatic and Editor-in-Chief of the Chemistry Central Journal. But most importantly, he was an inspiring scientist and evangelist of the open science and open access movement.
We have an opening for a Ph.D. position in Chris Steinbeck’s cheminformatics and metabolism team at the European Bioinformatics Institute (EBI) in Cambridge, UK.
Ph.D. topics are available in a wide range of areas such as analysis of metabolomics experiments, metabolism, computational natural product biochemistry, elucidation of natural products, text mining and image processing, and more. Applications should be submitted through the EMBL International Ph.D. programme. Ph.D. students successfully pursuing and completing their projects will retrieve their Ph.D. from the University of Cambridge, UK.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.